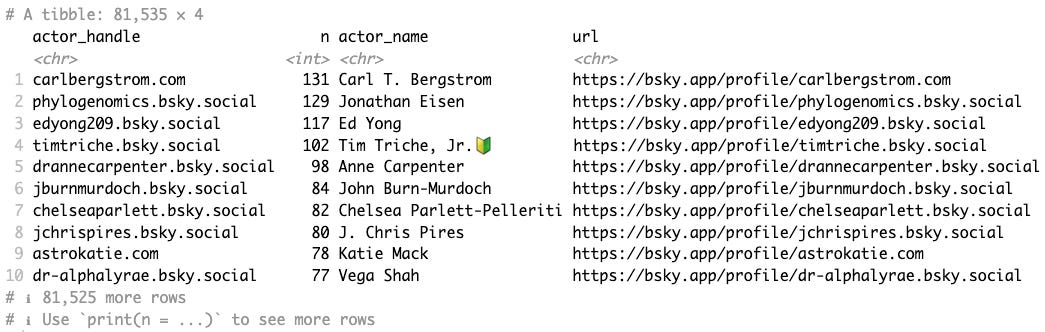
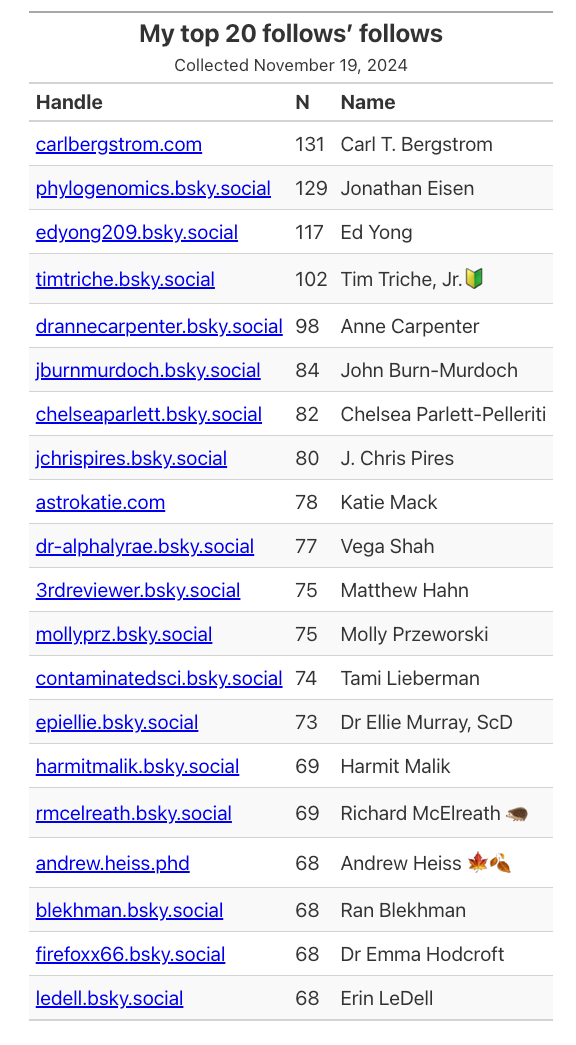
Reposted from https://blog.stephenturner.us/p/tech-im-thankful-for-2024
Data science and bioinformatics tech I'm thankful for in 2024: tidyverse, RStudio, Positron, Bluesky, blogs, Quarto, bioRxiv, LLMs for code, Ollama, Seqera Containers, StackOverflow, ...
It’s a short week here in the US. As I reflect on the tools that shape modern bioinformatics and data science it’s striking to see how far we’ve come in the 20 years I’ve been in this field. Today’s ecosystem is rich with tools that make our work faster, better, enjoyable, and increasingly accessible. In this post I share some of the technology I'm particularly grateful for — from established workhorses that have transformed how we code and analyze data, to emerging platforms that are reshaping scientific communication and development workflows.
The tidyverse: R packages for data science. Needs no further introduction.
devtools + usethis + testthat: I use each of these tools at least weekly for R package development.
Rstudio, Positron, and VS Code: Most of the time I’m using a combination of VS Code and RStudio. My first experience with Positron was a positive one, and as several of my dealbreaker functionalities are brought into Positron, I imagine next year it’ll be my primary IDE for all aspects of data science.
Bluesky. This place feels like the “old” science Twitter of the late 00s / early teens. I wrote about Bluesky for Science to get you started. It’s so great to have a place for civil and good-faith discussions of new developments in science, to be able to create my own algorithmic feeds, and to create thermonuclear block/mute lists.
Slack communities. There are many special interest groups and communities with Slack/Discord communities open to anyone. A few that I’m a part of:
Blogs. Good old 2000s-era long form blogs. I blogged regularly at Getting Genetics Done for nearly a decade. Over time, Twitter made me a lazy blogger. My posts got shorter, fewer, and further between. I’m pretty sure the same thing happened to many of the blogs I followed back then. In an age where so much content on the internet is GenAI slop I’ve come to really appreciate long-form treatment of complex topics and deep dives into technical content. A few blogs I read regularly:
Simon Willison’s Weblog: https://simonwillison.net
One Useful Thing (Ethan Mollick): https://www.oneusefulthing.org
Ground Truths (Eric Topol): https://erictopol.substack.com
Asimov Press: https://www.asimov.press
Century of Biology (Elliot Hershberg): https://centuryofbio.com
Bits in Bio: https://bitsinbio.substack.com
Connected Ideas Project (Alexeander Titus) connectedideasproject.com
Owl Posting (Abhishaike Mahajan): https://www.owlposting.com
nf-core blog: https://nf-co.re/blog
R Weekly: https://rweekly.org/
Quarto: The next generation of RMarkdown. I’ve used this to write papers, create reports, to create entire books (blog post coming soon on this one), interactive dashboards, and much more.
Zotero: I’ve been using Zotero for over 15 years, ever since Zotero was only a Firefox browser extension. It’s the only reference manager I’m aware of that integrates with Word, Google Docs, and RStudio for citation management and bibliography generation. The PDF reader on the iPad has everything I want and nothing I don’t — I can highlight and mark up a PDF and have those annotations sync across all my devices. Zotero is free, open-source, and with lots of plugins that extend its functionality, like this one for connecting with Inciteful.
bioRxiv: bioRxiv launched about 10 years ago and every year gains more traction in the life sciences community. And attitudes around preprints today are so much different than they were in 2014 (“but what if I get scooped?”).
LLMs for code: I use a combination of GitHub Copilot, GPT 4o, Claude 3.5 Sonnet, and several local LLMs to aid in my development these days.
Seqera Containers: I’m not a Seqera customer, and I don’t (yet) use Seqera Containers URIs in my production code, but this is an amazing resource that I use routinely for creating Docker images with multiple tools I want. I just search for and add tools, and I get back a Dockerfile and a conda.yml file I can use to build my own image.
Ollama: I use Ollama to interact with local open-source LLMs on my Macbook Pro, for instances where privacy and security is of utmost concern.
StackOverflow: SO used to live in my bookmarks bar in my browser. I estimate my SO usage is down 90% from what it was in 2022. However, none of the LLMs for code would be what they are today without the millions of questions asked and answered on SO over the years. I’m not sure what this means for the future of SO and LLMs that rely on good training data.